![]()
![]()
![]()
![]()
|
|
|
|
|
|
||
The InetProtUtils API provides functionality to handle URIs, such as extracting URI components, constructing and modifying a URI, text utilities, and URI component utilities required to work with URIs.
|
|
The clients that make use of this API need to be familiar with these standards:
RFC 2396, for Uniform Resource Identifiers (URI)
RFC 1123 for internet date and time specifications
WAP WSP for HTTP functionality.
|
|
The component has the following key concepts:
A Universal Resource Identifier (URI) is a formatted string that identifies the location and name of a resource, for instance a web page address.
Let us consider this URI:
http://user:[email protected]:80/top_path/foo.htm?checkme#ref
The URI can be split into components as follows:
|
In a URI, the user information, host and port information put together is called authority. Format for authority looks like this:
[[email protected]]host[:port]
where, user-info may consist of a user name and,
optionally, scheme-specific information about how to gain authorisation to
access the server, for example, password. port specifies the port
number.
|
|
InetProtUtils API (inetprotutils.dll) is used by the
following components:
App services
DM / DS
Content Handling Framework
Java MIDlet installer
Symbian OS services:
Certificate lib
Multimedia
|
|
The following classes are used for creating, parsing and modifying the URI.
|
The following classes are used for parsing delimited data in the URI.
|
The following classes are used for encoding and decoding WSP headers.
|
The following diagram shows the InetProtUtils classes and their relationships.
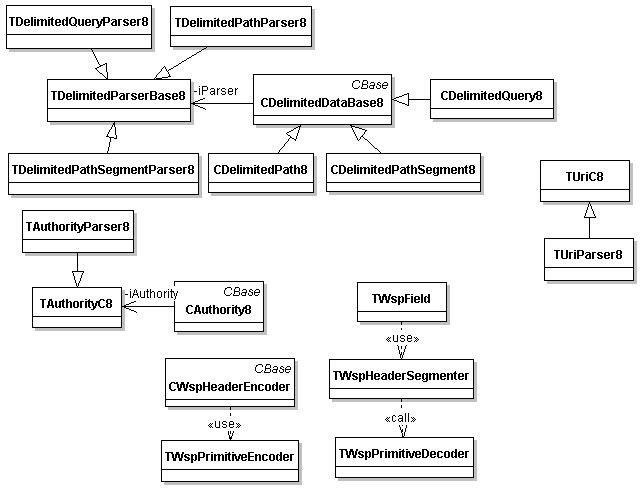
Class diagram for InetProtUtils
|
|
The applications that use HTTP transport framework use InetProtUtils API. The utilities may also be useful for applications which deal with internet strings or URIs, like mail or IM applications.
The following tasks can be performed using InetProtUtils:
URI can be created in different ways. It can be created from parts,
from file or by resolving two URIs using CUri8 class.
For more information on creating a URI, refer to How to create a URI.
To check if the components in the URI are syntactically correct as per
the four main components and fragment identifier, one needs to parse the URI.
Use TUriParser8 class when you need to parse a URI.
For more information on parsing, refer to How to parse a URI.
URI classes namely, CUri8,
TUriC8 and TUriParser8 provide
functionality for parsing generic and SIP URIs. CUri8
class provides a reference to a TUriC8 object so that the
non-modifying functionality can be used. TUriC8 is used to
get information about a URI.
Components from the URI can be extracted using extracting methods
provided by TUriC8 class. You can extract the authority
component using TAuthority8 class.
For more information on getting URI components, refer to How to extract the URI components.
A fully qualified filename can be generated from a file URI object.
TUriC8::GetFileNameL() provides this functionality. The
path component encodes the file's location on the file system.
For more information, refer to How to generate filename from URI.
You can check if components in a given URI are valid using
TUriParser8::Validate(). This validates only SIP and SIPS
scheme components.
For more information, refer to How to validate a URI.
URI components are seperated into segments using delimiters. You can
parse this delimited data. TDelimitedXxxxParser8 classes provide
the functionality to parse the delimited data, extract the current segment and
parse the string for the next segment.
For more information, refer to How to parse the delimited data.
The delimiters and segments of data within a URI can be added, removed
and parsed. This functionality is provided by CDelimitedXxxx8
classes.
For more information, refer to How to modify the data and the delimiter.
The reserved and unsafe data in the URI is escape encoded and decoded
using EscapeUtils class. It also supports converting
Unicode data (16-bit descriptor) into UTF8 data (8-bit descriptor) and
vice-versa. For more information, refer to
How to escape encode and decode.
The data in a URI can be manipulated using various text parsing
utilities that are used typically in HTTP headers.
InetProtTextUtils provides functionaliy to:
Remove the leading/trailing contiguous white space characters from the descriptors
Convert the decimal/hexadecimal value to descriptor and vice versa.
Extract tokens from:
a list, which is a string separated with a character, for example, abc, def, ghi.
quoted strings in text.
It supports both Unicode and UTF-8 formats. For more information on text manipulations, refer to How to manipulate URI data.
Additional functionality to create a URI from unicode descriptor is
provided by UriUtils class. It also allows to translate
unsafe characters to UTF8 and escape-encode.
For more information, refer to Using URI utilities.
To store dates in universal times and parse the internet dates into
TDateTime dates, TInternetDate is
used.
For more information, refer to Using date and time utilities.
The WSP header information is encoded and decoded using
CWspHeaderEncoder. It uses
TWspPrimitiveEncoder to convert the data into binary
strings.
For more information, refer to How to encode and decode WSP header.
Note: Use Cxxx classes to create text from parts and TxxParser classes to parse text into components.
|
Copyright ©2008 Symbian Software Ltd. |
|
![[Top]](https://docs.huihoo.com/symbian/s60-3rd-edition-cpp-developers-library-v1.1/GUID-35228542-8C95-4849-A73F-2B4F082F0C44/html/SDL_93/a_stock/btn_top.gif)