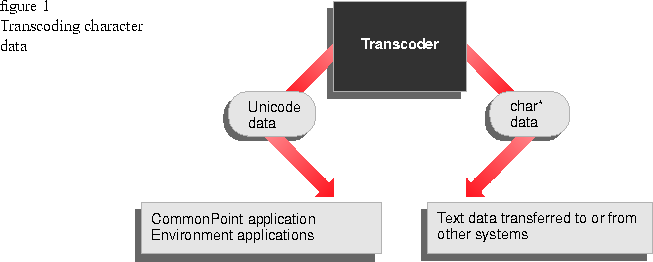
The CommonPoint application system storage mechanism for all character data is based on the Unicode character encoding standard. The Unicode character set contains a code for every character in every major world script, along with a wide set of symbols, punctuation, and control characters. Because you store and access every character using the Unicode system, regardless of its script or natural language, you can manipulate text much more simply in the CommonPoint application system than in other environments that require multiple code pages to support different character sets. Generally, Unicode text can be used anywhere in the CommonPoint application system.
For transferring character data to and from other systems, the CommonPoint application system also includes a set of transcoders that convert character data between Unicode and other character encoding sets--for example, the ASCII (ISO 8859/1) or Macintosh" character encodings. You can use these transcoders anywhere you need to handle non-Unicode character data--for example, within networking services or electronic mail applications that transfer text to and from other systems.