![]()
![]()
![]()

Transliterators are also used to create input methods for ideographic languages. See "Input Method framework" on page 186 for a description of input methods.
Transliterators are typically selected for inclusion in a typing configuration by end users. They can be chained together to process typing input in a specific way. The Typing framework will eventually provide an interface allowing end users to directly manipulate transliterators. You can also use transliterators programmatically for tasks such as capitalizing title text.
TTransliterator is the abstract base class providing the protocol for transliterators. Transliterators have localizable names and are supported by the locale mechanism.
THexTransliterator is a concrete transliterator class that provides transliteration from hexadecimal numbers between one and four digits into their Unicode representations. Hexadecimal numbers are read using the syntax %xxxx, for example, %12f3. You can use this class directly; it was not designed to be subclassed.
TRuleBasedTransliterator is a concrete class that encapsulates a set of context-sensitive rules for transliterating text, along with a parallel set of rules that perform the reverse transliteration. These rules can be localized, allowing the same transliterator to be used in different locales.
TTransliterateRule encapsulates a single transliteration rule, containing the input text, result text, and, optionally, preceding and succeeding context information. Use TTransliterateRulesIterator to iterate through the rules contained by a particular transliterator instance.
TTransliteratorHandle provides a lightweight mechanism for referencing a particular instance of a transliterator class. Because a transliterator encapsulates a large amount of data, use this class to access a transliterator unless you need to specifically access individual rules. You can create a handle referencing one of the existing transliterators using the transliterator's name. For example:
Transliterator classes
The following classes implement transliterators: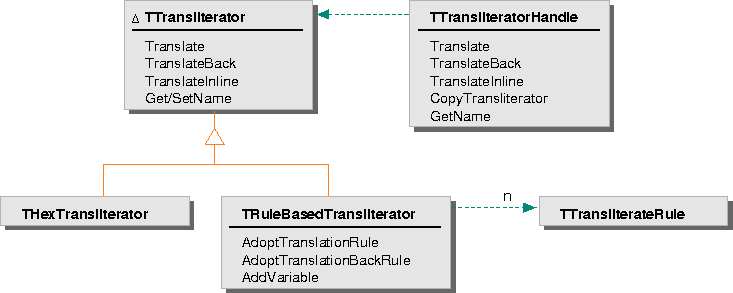
TTransliteratorHandle aHandle(TTransliteratorHandle::kJapaneseTransliterator);
Available transliterators
The system currently provides the following rule-based transliterators:
NOTE  Some of the files the CommonPoint application system provides that contain transliteration tables were created using the Macintosh character set; they may not display correctly on other platforms. These transliteration tables still work correctly, but you may not be able to view them. This will be fixed in a later release.
Some of the files the CommonPoint application system provides that contain transliteration tables were created using the Macintosh character set; they may not display correctly on other platforms. These transliteration tables still work correctly, but you may not be able to view them. This will be fixed in a later release.
| Rule | Input | Result | Preceding context | Succeeding context | |
| Change red to green | red | green | NIL | NIL | |
| Change red light to green light | red | green | NIL | light | |
| Change red light to red signal | light | signal | red | NIL |
You can also specify range variables for transliteration rules. Range variables allow you to provide a limited amount of wildcard matching for rule input and context fields. The variable is a single character, which cannot itself appear in any rule. It can be set to any range or set of characters (for example, AEIOU or A-Z). You can then use these variables within rules. Whenever a character in the variable range or set appears in that field, the rule is applied.
You can also create inverse rules. Whenever a character in the variable range or set does not appear in that field, the rule is applied. For example, you could create a variable value equal to all Roman letters (the ranges a-z and A-Z) and you could use the same value for an inverse variable to denote any nonletter character.
Iterating through transliterator rules
If you need access to the rules contained by a particular rule-based transliterator, use TTransliterateRulesIterator. To do this:
TRuleBasedTransliterator aTranslit(TTransliteratorHandle::kJapaneseTransliterator); TTransliterateRulesIterator* iterator = aTranslit.CreateIterator; TTransliterateRule translitRule = iterator.First(); // Process rule and continue iteration. delete iterator;