![]()
![]()
![]()
kNoRoundTrip transcoding scope, which means that any characters without a one-to-one mapping in the target set are converted to a standard substitution character. Override this to use a different scope. See "Handling exception characters" on page 30 for more information.When you convert text to Unicode, the transcoder converts text data from a character string (char*) and appends it to a TText instance. Again, you manage the storage for the target text object. The transcoder appends the converted text at the end of the text object. If the text object already contains text, the transcoder inserts the converted text after the existing text.
The abstract class TTranscoder provides the basic protocol for transcoding characters both to and from Unicode. Call the following TTranscoder member functions to perform conversions:
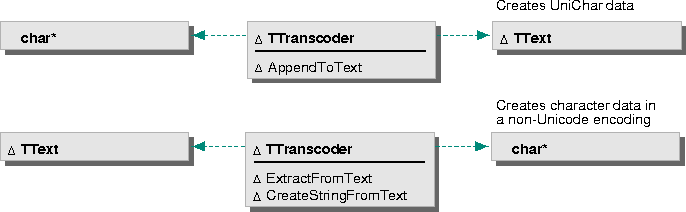
Converting character
data to Unicode
This example illustrates how to convert a string of ASCII characters to Unicode using TASCIITranscoder. The converted data is appended to the end of the text instance unicodeText.
unsigned char myASCIIString[] = "ASCII character string";
unsigned long stringLength = strlen(myASCIIString);
TStandardText unicodeText;
TASCIITranscoder transcoder;
TTextCount numCharsConverted = transcoder.AppendToText(myASCIIString,
stringLength, unicodeText);
The TTranscoder::CreateStringFromText member function provides the simplest way to convert text from Unicode. This function returns a null-terminated string that you should delete when you are finished.
This example shows how to use TASCIITranscoder to convert the Unicode text in the text instance unicodeText to ASCII character data, which is placed in the character string myASCIIString.
unsigned char* myASCIIString = NIL;
TASCIITranscoder transcoder;
TTextCount stringLength = transcoder.CreateStringFromText(myASCIIString,
unicodeText);
// Process myASCIIString...
delete myASCIIString;
This example calculates the required buffer size and uses the ExtractFromText function to convert the text in unicodeText to ASCII character data. The ASCII character data is returned in asciiCharBuffer. The length of the output string is returned in charBufferSize.
TASCIITranscoder transcoder();
// Calculate required buffer size and create the buffer.
TTextCount charBufferSize = unicodeText.GetLength() *
transcoder.GetMaximumBytesPerCharacter();
unsigned char* asciiCharBuffer = new (unsigned char)[charBufferSize];
// Perform the text conversion.
transcoder.ExtractFromText(unicodeText, TTextRange(0,unicodeText.GetLength()),
asciiCharBuffer, charBufferSize);
The following are samples of functions you can use to convert text between ASCII and Unicode. This code, like the CommonPoint ASCII transcoder, converts the ASCII new line and carriage return characters to the Unicode characters TGeneralPunctuation::kLineSeparator and TGeneralPunctuation::kParagraphSeparator.
const char kASCIINewLine = 0x0A;
const char kASCIICarriageReturn = 0x0D;
const char kASCIISubstitute = 0x1A;
const char kEndOfASCII = 0x7F;
TTextCount
ASCIIToUnicode(char* ascii, UniChar* unicode)
{
char aChar;
UniChar* unicodePtr = unicode;
while (aChar = *ascii++)
{
switch (aChar) {
case kASCIINewLine:
*unicodePtr++ = TGeneralPunctuation::kLineSeparator;
break;
casekASCIICarriageReturn:
*unicodePtr++ = TGeneralPunctuation::kParagraphSeparator;
break;
default:
{
if (aChar <= kEndOfASCII)
*unicodePtr++ = (UniChar) aChar;
else
*unicodePtr++ = TUnicodeSpecial::kReplacementCharacter;
break;
}
}
}
return unicodePtr-unicode;
}
TTextCount
UnicodeToASCII(UniChar* unicode, char* ascii)
{
UniChar aChar;
char* asciiPtr = ascii;
while (aChar = *unicode++)
{
switch (aChar)
{
case TGeneralPunctuation::kLineSeparator:
*asciiPtr++ = kASCIINewLine;
break;
case TGeneralPunctuation::kParagraphSeparator:
*asciiPtr++ = kASCIICarriageReturn;
break;
default:
{
if (aChar <= kEndOfASCII)
*asciiPtr++ = (char) aChar;
else
*asciiPtr++ = kASCIISubstitute;
break;
}
}
}
}
This table compares the use of the Unicode characters TGeneralPunctuation::kLineSeparator and TGeneralPuncutation::kParagraphSeparator with the use of the line feed (LF) and carriage return (CR) characters in the character encoding systems used by some other systems.
|
CommonPoint application system |
UNIX | Macintosh System 7 | DOS |
| TGeneralPunctuation:: kLineSeparator | LF | LF | LF |
| TGeneralPunctuation:: kParagraphSeparator | LF | CR |
CR LF (character sequence) |